ReLi3D
Relightable Multi-view 3D Reconstruction with Disentangled Illumination

ReLi3D — Reconstructing geometry, lighting and materials from multiple posed views in under one second.
Overview
ReLi3D is a unified feed-forward pipeline that turns sparse posed RGB views into a complete, relightable 3D asset in under one second. In one pass, it reconstructs geometry, spatially varying physically based materials, and coherent HDR environment illumination. Our central insight is that multi-view constraints are the key to material-lighting disentanglement. When multiple views observe the same surface under shared illumination, cross-view consistency sharply reduces the ambiguity that makes single-view inverse rendering ill-posed.
Method
ReLi3D uses a shared cross-conditioning transformer to fuse an arbitrary number of masked views into a unified triplane representation. Two coupled prediction paths then recover geometry and spatially varying materials alongside environment lighting.
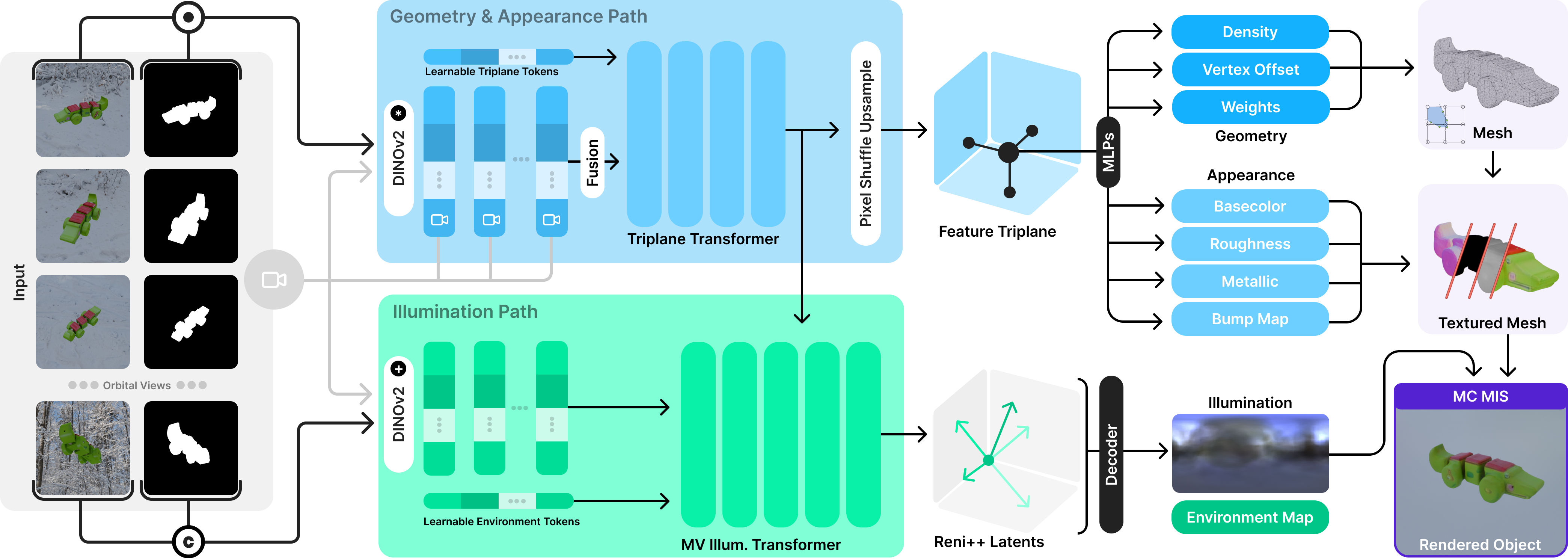
Multi-view Fusion — Each input view is encoded with DINOv2 features and camera-aware modulation. A randomly selected hero view forms the query stream, while the remaining views are compressed into a compact cross-attention memory. This two-stream fusion produces view-consistent triplane features and supports flexible view counts at inference.
Two-path Prediction — From the shared triplane, a geometry-and-appearance path predicts density and svBRDF parameters (albedo, roughness, metallic, and normal perturbations), while an illumination path predicts a RENI++ latent code and rotation for a coherent HDR environment map. Joint training forces both paths to explain the same observations with a physically plausible decomposition.
Differentiable Rendering and Training — A differentiable physically based renderer with Monte Carlo integration and multiple importance sampling couples both paths during training. Together with mixed-domain supervision from synthetic PBR assets, synthetic RGB-only renders, and real UCO3D captures, this stabilizes disentanglement and improves real-world generalization.
Results
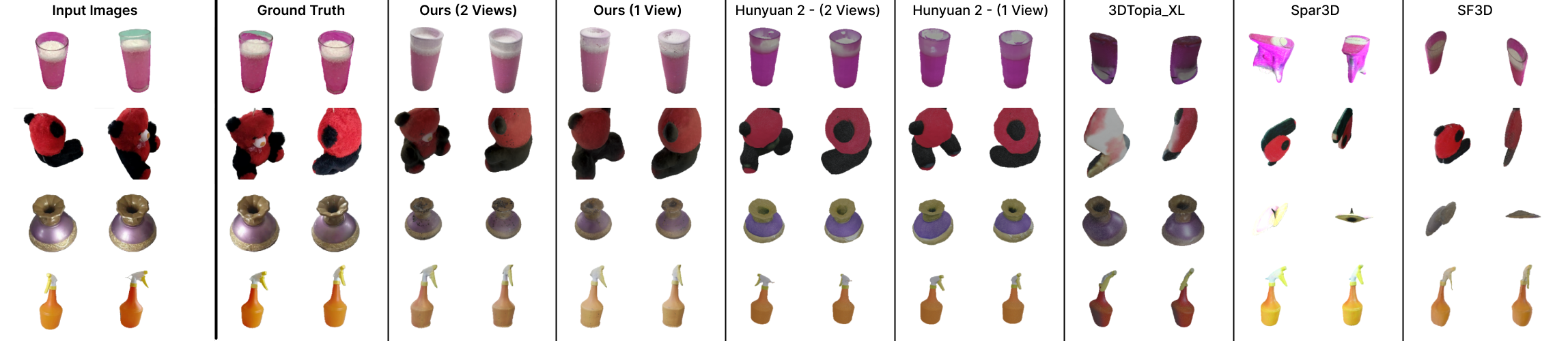
Across synthetic and real-world benchmarks, ReLi3D improves relighting fidelity, image quality, and material reconstruction over recent feed-forward and generative baselines while remaining interactive (about 0.3 seconds per object).

Material and Illumination Disentanglement — ReLi3D predicts fully spatially varying PBR channels and a coherent environment map from the same sparse inputs. As more views are provided, base color becomes sharper, roughness and metallic estimates become more stable, normals improve, and predicted illumination better matches sky color and dominant light direction.


Reconstruction and Generalization — Although geometry is not the sole optimization target, ReLi3D remains competitive on 3D reconstruction while delivering strong image and relighting quality. Mixed-domain training enables robust performance on real captures such as Stanford ORB and UCO3D, and quality improves steadily from single-view to multi-view input with minimal runtime overhead.

Limitations and Outlook
Failure cases mainly appear under out-of-domain lighting, especially scenes with multiple intense localized light sources, where some illumination can remain baked into the recovered materials. In addition, triplane resolution currently limits the finest recoverable texture and geometric detail. Even with these limits, ReLi3D provides a practical foundation for fast relightable reconstruction and clear next steps toward higher-resolution modeling and stronger illumination priors.
Citation
More Information
Open Positions
Interested in persuing a PhD in computer graphics?
Never miss an update
Join us on Twitter / X for the latest updates of our research group and more.
Recent Work
Acknowledgements
The authors thank Stability AI for hosting Jan-Niklas Dihlmann as an intern during this work. This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy—EXC number 2064/1—Project number 390727645. This work was supported by the German Research Foundation (DFG): SFB 1233, Robust Vision: Inference Principles and Neural Mechanisms, TP 02, project number: 276693517. This work was supported by the Tübingen AI Center. The authors thank the International Max Planck Research School for Intelligent Systems (IMPRS-IS) for supporting Jan-Niklas Dihlmann.